可以從Part 1提到的設定檔裡看出來,相對psa的持久暫存區,stage層則是整合層內的非持久暫存。
dbt_project.ymlmodels:
...
automate_dv:
stage:
+materialized: view
+schema: automate_dv
...
這裡+materialized: view的意思是,在執行資料處理管道的時,會以create view as ... 的方式創建資料。換句話說,在物化這層不會進行任何實際的資料處理,而只有到在下一層的運行(runtime)才會實際執行。
這樣的設計主要是為了簡化raw vault層的設計,將所有的hash key都在同一個view上事先定義好,就不需要在衛星(satellite)或鏈接(link)表上回述中心(hub)表。這樣也讓下一層處理可以更有效的做到平行處理。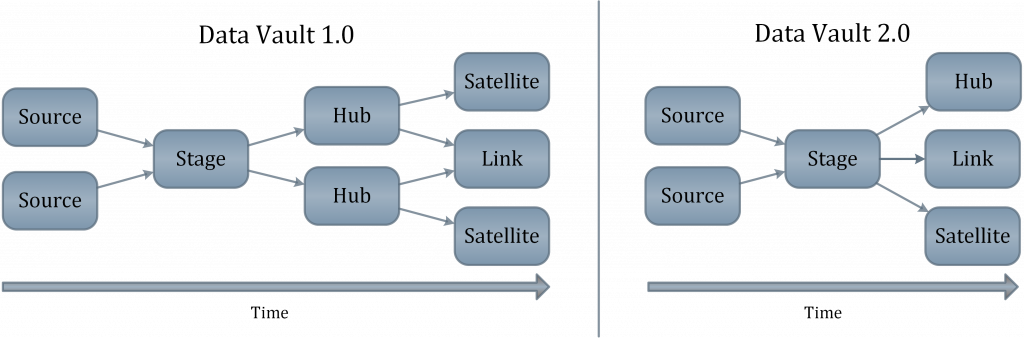
models/automate_dv/stage/adv__stg_salesforce_opportunities.sql這個檔案分成兩大部分,定義和設定變數、與將變數映射到巨集函數上。函數輸入的部分基本上是樣板化的(boilerplate),而比較重要的是定義和設定變數的部分:
{%- set yaml_metadata -%}
source_model: "psa_salesforce_opportunities"
derived_columns:
RECORD_SOURCE: "!SALESFORCE__OPPORTUNITIES"
LOAD_DATETIME: "DATECREATED"
EFFECTIVE_FROM: "MODIFIEDDATE"
...
{%- endset -%}
derived_columns的部分是為了定義DV 2.0的規定性要求,讓每一筆紀錄都有明確指出的資料出處(RECORD_SOURCE)、創建時間(LOAD_DATETIME)、有效時間(EFFECTIVE_FROM)。從原始資料層的資料列上可以看出,在資料源系統上是沒有考慮有效CDC的資料設計的,通過
{%- set yaml_metadata -%}
...
hashed_columns:
OPPORTUNITY_PK: "OPPORTUNITYID"
ACCOUNT_PK: "ACCOUNTID"
OPPORTUNITY_ACCOUNT_PK:
- "OPPORTUNITYID"
- "ACCOUNTID"
OPPORTUNITY_HASHDIFF:
is_hashdiff: true
columns:
- "AMOUNT"
- "PROJECT_NAME"
- "OPPORTUNITY_NAME"
- "STAGE"
- "CLOSE_DATE"
{%- endset -%}
這裡是所有散列值的定義。雖然說AutomateDV沒有嚴格執行列命名約定(column naming conventions),但這裡還是按照列命名約定使用_PK來辨識各個唯一鍵(Primary Key)和_HASHDIFF來辨識散列值差。
嚴格來說,這裡的ACCOUNT_PK其實是Accounts實體的唯一鍵,在這個表內應該算是外鍵(Foreign Key)。但為了統一各個表上的列命名還有寫下游query的方便,這裡就都定義成_PK。
另外就像我們之前提到的,hashdiff主要的用途是為了快速比對敘述性資料,而所以這裡包含在OPPORTUNITY_HASHDIFF裡面也只有Opportunity這個實體的敘述性資料列。
還有一層raw_vault就終於完成了基本DV的實踐案例了!希望解釋的還算清楚。stage層主要是為了raw_vault的鋪墊,而有很多細節到實際看到資料管道下游的時候應該就會比較容易理解。
對 dbt 或 data 有興趣 :wave:?歡迎加入 dbt community 到 #local-taipei 找我們,也有實體 Meetup 請到 dbt Taipei Meetup 報名參加

